[4. NeRF] ECCV 2020
relate work
Novel view Synthesis
:N대의 카메라를 통한 input을 통해 임의의 시점에서 본 대상의 모습을 합성
like 영화 매트릭스 총알이 움직이는 장면
parallax Effect
: 가까이 있는 것은 픽셀이동이 크고 먼 것이 있는 것은 픽셀이동이 적다.
so , 3d space에 대한 Analysis가 필수적임!!
pinhole Camera model

실제 세상의 위치 물체들이 어디에 위치해 있고 길이가 어디에 있는지 알아낼 수 있음.
so, 실제의 위치나 거리와 camera 정보간의 관계
Camera 정보와 카메라와 대상간의 거리(Depth)를 알아야함.

Normalized Plane
Depth=1 (m)인 평면 위로 모든 점을 Projection!! 하는 것임.
3D를 2D로 전환하는 과정이며 m 단위를 pixel단위로 바꾸는 과정이 필요함
거기서 intrinsic parameter (카메라 정보가 필요한 것임)

Extrinsic Parameter

NeRF

N개의 시점에서 찍은 2D image ==> 임의의 시점에서 찍은 2D image를 만드는 것이 핵심 목표임!!
Neural Radiace Field

3D data를 통째로 모델링 하겠다!!
이미지: 각 위치에 pixel 값을 저장한 Table의 형태
Neural Radiance Field: 각 위치 값을 input으로 주면 output으로 RGB 값을 연산하는 함수의 형태를 말하는 것임.
pixel 값 : 한 Ray 위에 존재하는 Point들의 RGB 값들의 Weighted SuM!!

input : 위치 ([-1,1]3 x,y,z)와 보는 방향 (Unit Vector: 보는 방향에 따라서 RGB값이 달라질 수 있다. )
output : RGB값과 Density(투명도의 역수 개념)
Deep neural Net으로 정의 하고 , 주어진 이미지들을 학습 시키는 것임.
projection
- 그 지점의 denstiy가 클수록 weight가 커야 한다.

- 그 지점을 가로 막고 있는 접들의 density의 합이 작을 수록 weight가 커야 한다.


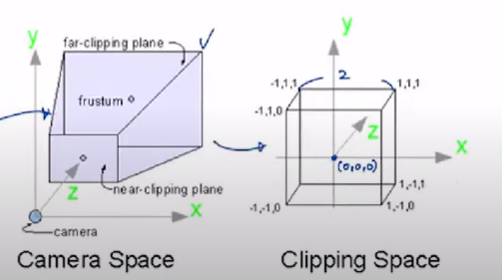
Normalized Device Coordinate(NDC)
real world scence을 cube 형태의 space로 변환



implemenetation
Hierarchical Volume Sampling

앞의 방법 처럼 Nc개의 t를 뽑고, coarse network를 학습시킨다.
coarse network를 통해 얻은 distribution(T(r))에 따라 Nf개의 t를 추가적으로 뽑는다.
(중점적으로 봐야 할 것을 더 보는 것임)
Nc+Nf개의 Sample을 이용하여 Fine Network를 학습시킨다.
Positional Encoding
[(x,y,z) ,d =(x^,y^,z^)] 6차원 ==> R,G,B, a 4차원으로 나타냄.
그러면 학습 결과가 좋지는 않음.
차원을 늘릴 필요가 있음 ==> cos , sin 으로 이용해서 차원을 높여 선명도를 높여야 함.

https://www.youtube.com/watch?v=zkeh7Tt9tYQ&t=617s
https://www.youtube.com/watch?v=zkeh7Tt9tYQ&t=617s